
Semantic collapse in RAGs by Stanford
Semantic collapse in RAGs by Stanford provides a way to keep on those MCP servers alive. After all … how do you know that you’re actually learning more, and not forgetting even more than you learn?
You test ? 🙂
Will be the first one when i see an MCP server tested around the clock for proper, deterministic return values.
Stanfors is the best -> dho.stanford.edu/wp-content/uploads/Legal_RAG_Hallucinations.pdf
Semantics asks what an expression means.
Logic asks whether an argument is valid or whether a statement follows from other statements.
A sentence can be semantically meaningful but still logically false. All birds can fly. Penguins are birds. ∴ Penguins can fly. Formally valid, but premise “All birds can fly” is false in reality.

Semantic collapse
In a Retrieval-Augmented Generation (RAG) system, semantic collapse is failure in retrieval where the answers are contextually wrong and increasingly generic without proper detailed meaning. In the end, it is a math problem.
Everyone thought RAG was the antidote to hallucinations. “Just plug in your docs and the model will stay grounded.” Semantic collapse kicks in, and your “AI over docs” quietly turns into a confident storyteller with a search problem in disguise.
Let us try and understand the notions.
How RAG Actually Works
RAG under the hood it’s painfully mechanical. Kinda just arrows pointing to their next of kin.
- You take a document (or chunk).
- You embed it into a high‑dimensional vector.
- Store those vectors in a database.
- After prompts embedding db does a nearest‑neighbor search.
In the early days, with a few thousand chunks, this feels amazing. Similar ideas naturally cluster. “Contract termination clause” lives near “notice period”. Retrieval feels sharp, sometimes even alive… until the horse is dead.
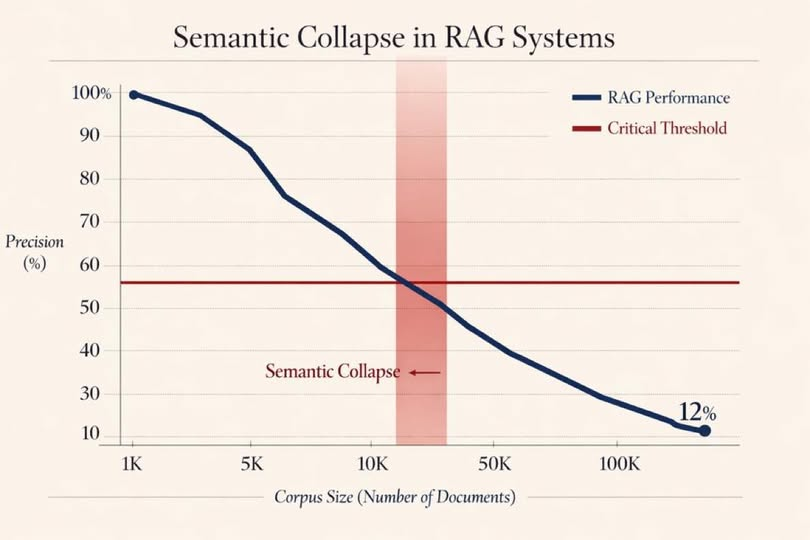
Critical mass of the vector space
Under roughly 10,000 documents, your vector space is relatively clean. Clusters are separated. Distances mean something. It is properly dividing the subjects into areas. Car subject are next to other car subjects, airplanes next to airplanes… fuel could be tricky but it depends on the vector length and tightness of the space.
- The space fills up.
- Clusters start to overlap. The training and separation of this gets more and more difficult.
- Distances compress.
Some math
Check a visualization out here – https://projector.tensorflow.org/
Mathematically, this is the curse of dimensionality. High‑dimensional spaces, almost all points sit near the outer shell, and everything becomes “kind of equally far” from everything else.
Resulting in Your nearest‑neighbor in the graph search still returns “similar” chunks, but “similar” has been flattened into “vaguely related in some embedding’s imagination.” Semantically. On math level it adds up, its close enough. We humans know better.
To the model, everything looks relevant – it is close but to the user the answers start to loose magic and logic.
Vectors stop vectoring
Core failure mode:
- You ask a precise question.
- The retriever pulls a mix of barely‑related chunks that look semantically “close” but are actually all over the place logically.
- The LLM, doing what it does best, weaves them into a smooth, polished answer.
Did it lie on purpose? No.
Stanford’s legal RAG study found that as document collections scale into the tens of thousands, precision tanks hard. At around 50,000 documents, retrieval quality degraded so badly that naive semantic search underperformed traditional keyword search.
That’s the punchline almost nobody wants to hear:
add more data, and your fancy semantic stack can become worse than dumb ctrl+f.
More Context ≠ More Truth
The instinctive “fix” people try to:
- Add more context windows.
- Retrieve more chunks and figure it out from a smaller scope.
- Give the model more to work with so it can easier narrow down the proper path.
Based on research it does the opposite. It amplifies it. It is like adding insult to injury.
If your retrieval is noisy, giving the LLM more noise just means it has more raw material to hallucinate from. It will happily stitch together three partially correct clauses, one outdated policy, and an unrelated FAQ into a very confident, very wrong conclusion.
You buried them under a pile of math and formatting.

Design problem, not a model issue
Once the space is saturated, similarity scores stop giving you a clean ranking of “best evidence.” You get a fuzzy neighborhood of “could be related,” and you hope the LLM / MCP can sort it out. It has a vibe it just feels right, like a hippie in the 60s.
Design structures
- Metadata and filters (jurisdiction, date, document type).
- Hierarchies (sections, parents, linked references).
- Task‑aware retrieval (what kind of answer are we constructing?).
- Guardrails (don’t let the model mix incompatible sources).
Without that, “AI over your docs” is just a glorified autocomplete sitting on top of an increasingly chaotic search index.
So What Do You Do About It?
Few hard rules to think about RAG design
- Treat “just dump all your docs in” as a red flag, not a feature.
- Measure retrieval precision as your corpus grows; don’t rely on vibes.
- Prefer systems that combine semantic search with filtering, ranking, and domain‑aware constraints.
- Design for evidence: show users which documents were used and let them inspect them.
Read more also on https://arxiv.org/html/2601.03052v1 – Detecting Hallucinations in Retrieval-Augmented Generation via Semantic-level Internal Reasoning Graph
What part of this breakdown feels most relevant to the systems you’re building right now—corpus growth, retrieval quality, or how the model actually uses the retrieved chunks?




