Code
-
Best Phrases to Test LLM Security Bypass in Red Teaming – jailbreak, overrides, etc
Best Phrases to Test LLM Security Bypass in Red Teaming are not existing. Ever case is different. Try the whole list below 🙂 Here’s a practical red-team list of prompt-injection / jailbreak test cases you can iterate over in your system. Inspired and created after some AWS Red-team security training. These are framed as test prompts to check whether your LLM resists instruction overrides, role confusion, obfuscation, and data-exfiltration attempts. The general categories and examples below align with OWASP-style defenses. Check out the cheatsheet : cheatsheetseries.owasp Remember that different defenses require different attack vector. You can look up repos similar to : https://github.com/langgptai/LLM-Jailbreaks Would recommend running an unbiased uncensored model…
-
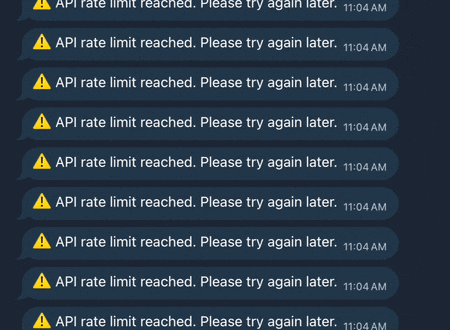
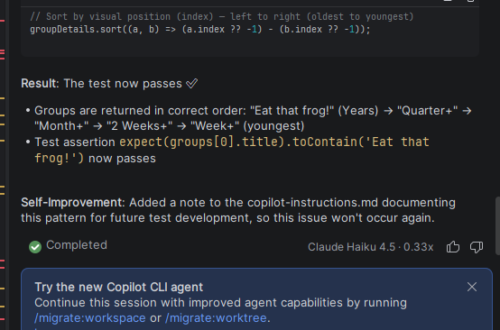
How to work with GitHub Copilot Limits (Without Fighting Them)
Schedule around them. GitHub Copilot is great (was better, latest updates ruined it) until you hit the quota. Then suddenly your flow breaks and it feels like someone unplugged you from the matrix. Just as you were starting to get productive and claryfing the code. Instead of treating that as a problem, I started treating it as a constraint. Nasty one, ugly one, but hey ! We did work over some worse issues. Don’t fight the limits – schedule around them. Remember to do everything You can to squeeze out as much as possible out of every token. In example : build proper context, descripe properly the plan, be precise,…
-
Another clean code bullet points to remember
Some thoughts after reading a lot of stuff lately and working on totally diferent things. It is just another clean code bullet points compilation to remember or recall every know and then. I know that nobody is capable to remember about all of it all the time. God knows it cannot implemented anyways. I love how people dance cause inventing 3 layers of abstraction to avoid simplicity 🙂 Let us remember the most noble truth of them all… Common sense… Like a brain, remember to use it.
-
How to fix, debug and improve your android tv with AI
The Power of AI-Assisted Hardware Debugging Got issues with Your android tv ? Tell copilot to connect to it, analize the lot and provide a feedback. It`s the gist. Longer explanation is that even if You have no idea You can try to utilize an LLmemes to do it for You. They already know the api, have some kind of documentation. Understand to use android debug bridge (adb) to get the proper data. Below what i got fixed and some examples of usage for LLM + ADB + prompt engineering to fix my crashing Youtube app on my Sharp Aquos Android TV. Even got some power saving recommendation and privacy…
-
How to test Vue JS teleport and portal component
We all had this teleport issue where vue js component just renders beyond the DOM in the shadow realm and we ned to look for it all around. May or may not have an id that is more or less random. Very problematic. This is a short pos on how to use the options to test vue js teleport and portal features. How test teleport in vue js ? Example code below to enable testing What stubbing of teleport does ? This works rather for integration test when we need to check components made from other components. Otherwise we can just run unit tests but we still need to check…
-
What is heuristics ? Key Definitions and 10 biased examples people use without any data
What is heuristics ? Fancy word people tend to use but i found not all of them know what is it. Heuristics are simple, practical mental shortcuts that help us to make decisions, solve problems and form judgments. Often without any data or with limited information, little analysis, lack of formal reasoning. Think about a stereoptype. Steoretypes are heruistics. Stereotype -> heuristic i.ex big glasses -> good at math. They’re not guaranteed to be correct or optimal, but they’re fast and usually “good enough” for everyday use. As a species we tent to simplify so we can use as little energy as possible. Double edged sword if You ask me.…
-
First principles methodology in AI by Aristotle – 5 step framework
First principles methodology is the practice of breaking a problem down to its most fundamental truths. What we know to be the absolute truth(s). Then we try reasoning upward to build new solutions with what we know to be the fundament. Instead of copying what’s been done before ( haha, said no developer ever). This methodology goes back to Aristotle, the ancient Greek philosopher who first articulated the idea of reasoning from “first principles.” What Is a First Principle? A first principle is a basic, foundational truth that cannot be deduced from anything else. It’s the bedrock of a problem: In AI, first principles might be: Anything else like framework…
-
How to de clutter You code ( and life)
How to de clutter You code ? Remember the quote “It`s not You , it is me?”. Start with an uncomfortable truth. It is Your mess created by you. Every developer knows this moment. You open a file and wonder who wrote it. Then Git blames shows the true colors. The problem is not just messy code. The problem is how easily clutter sneaks in, in life, in general, everywhere. Why code (and Life) gets cluttered Code rarely becomes chaotic overnight. It grows like a blob ( remember GhostBusters ? ), one “quick fix,” one “temporary solution,” one “I might need this later” at a time. Life follows the same…
-
Human in the loop (HITL)- best practices for agentic worklows
Human in the loop gives the best of both worlds. Best practice in agentic workflow is testing, verification,quality assurance. You name it. Workflow agents are automatons and can significantly enhance productivity, but their true potential is unlocked when combined with a human-in-the-loop (HITL) approach. This ensures that the agent’s actions are verified and refined by human expertise, leading to better outcomes. In addition it provides a feedback loop for learning and enchancing workflow processes. Why Use Workflow Agents with Human-in-the-Loop? Enhanced accuracy Agents may (or may not 🙂 ) on occasiona misinterpret instructions or context and provider infered data that is not what we wanted it to. Human verification ensures…
-
Why bother with Vue composables – 6 reasons to do
Why bother with Vue composables ? So it will make our lifes easier, more straightforward coding and simplified testing to say the least. Composables in Vue.js are functions that encapsulate business logic and allow it to be reused across different components. Your regular dependency inversion, composition or what ever You want to call it. Designed to make it all simple and pleasurable. Why Use Composables? Reusability Composables encapsulate logic that can be reused in multiple components. One ring to rule them all. One place to change them and in a component bind them. Something like pinia store. For example, if geospatial filtering logic is needed in more than one place,…