-
Best Phrases to Test LLM Security Bypass in Red Teaming – jailbreak, overrides, etc
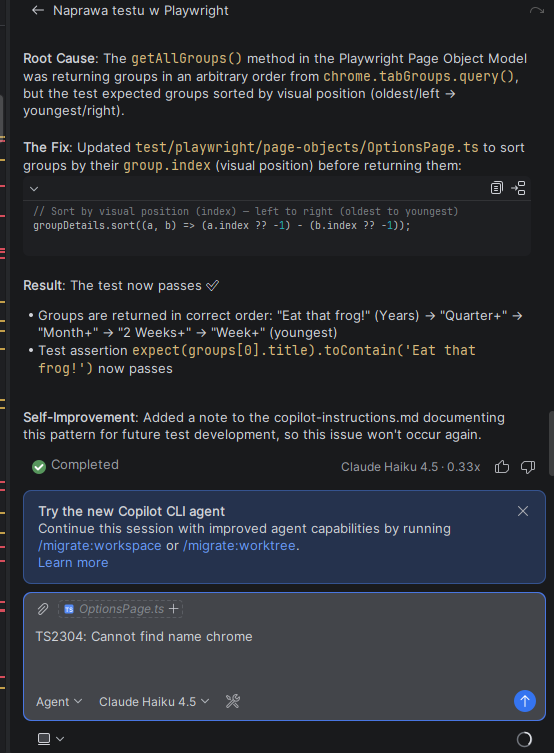
Best Phrases to Test LLM Security Bypass in Red Teaming are not existing. Ever case is different. Try the whole list below 🙂 Here’s a practical red-team list of prompt-injection / jailbreak test cases you can iterate over in your system. Inspired and created after some AWS Red-team security training. These are framed as test prompts to check whether your LLM resists instruction overrides, role confusion, obfuscation, and data-exfiltration attempts. The general categories and examples below align with OWASP-style defenses. Check out the cheatsheet : cheatsheetseries.owasp Remember that different defenses require different attack vector. You can look up repos similar to : https://github.com/langgptai/LLM-Jailbreaks Would recommend running an unbiased uncensored model…
-
Where to get data for my machine learning project
Where to get data for my machine learning project is a olot simpler. There are multiple sources You can use freely. Getting good data is usually harder than building the model itself. Without solid data on the input there is no way you wil get any decent answer. The upside of this struggle is that there’s a huge amount of public data out there ready for grabs. On the other hand of you get bad data you end up with something like below…. ( bad data beeing the memory registry … ) Remember that it is up to You to decide if the data is worth anything. Good luck 😉…
-
Improve your AI instruction on the fly …
Improve your AI instruction on the fly is easily doable with a simple set of generic instructions. Start as always with something basic, nothing fancy. Then move forward keeping in mind my favorite principle “First get it work, then make it better“. This will improve your instructions for any llm on its own. Below an example that works for me. Especially when i tell my LLmem that it is a nice soluion, i like it and good job. Instruction example That`s all folks ! Improve your AI instruction on the fly is nothing more then a feedback loop that is computed every time. Remember to keep overall instructions not too…
-
How to work with GitHub Copilot Limits (Without Fighting Them)
Schedule around them. GitHub Copilot is great (was better, latest updates ruined it) until you hit the quota. Then suddenly your flow breaks and it feels like someone unplugged you from the matrix. Just as you were starting to get productive and claryfing the code. Instead of treating that as a problem, I started treating it as a constraint. Nasty one, ugly one, but hey ! We did work over some worse issues. Don’t fight the limits – schedule around them. Remember to do everything You can to squeeze out as much as possible out of every token. In example : build proper context, descripe properly the plan, be precise,…
-
How to make an icon for 15 cents ?
How to make an icon for 15 cents ? Use AI. Try locally something like https://huggingface.co/models?pipeline_tag=text-to-image&sort=trending&search=ideogram This is how i made an icon for my browser extention and it cost me 15 cents. In Poland i wouldn`t buy any kind of ice cream for that and here… i have myself a nice icon for my browser extension / plugin. Best way to generate an SVG logo, for me, personally. Just use the openrouter chat option and provide some inputs, leave eveyrthing on auto. Why SVG? Cause You can easily edit it in any txt editor. It is liightweight. Scales. Cause it is text and not binary data. You can remove…
-
Context engineering vs prompt engineering. 10+ examples
Context engineering vs prompt engineering might sound similar. One is subset of the other. Early in the LLM era everyone who knew how to form sentences, and at least vaguely, describe what they want became a “prompt engineer”. Tweaking words, hashtags, ‘special’ commands, using roles, adding examples, using words to dive deep into different embedded spaces of knowledge in hope to force the model “gets it.” That’s Prompt Engineering – crafting clever one-shot instructions like “You are an expert X. Do Y like Z.” Context engineering vs prompt engineering synergies across both. System got fat and grew bigger, then we realized prompts alone aren’t enough. What the model knows, when…
-
Semantic collapse in RAGs by Stanford
Semantic collapse in RAGs by Stanford provides a way to keep on those MCP servers alive. After all … how do you know that you’re actually learning more, and not forgetting even more than you learn?You test ? 🙂 Will be the first one when i see an MCP server tested around the clock for proper, deterministic return values. Stanfors is the best -> dho.stanford.edu/wp-content/uploads/Legal_RAG_Hallucinations.pdf Semantics asks what an expression means. Logic asks whether an argument is valid or whether a statement follows from other statements. A sentence can be semantically meaningful but still logically false. All birds can fly. Penguins are birds. ∴ Penguins can fly. Formally valid, but…
-
Anthropic Opus 4.5 and sonnet hardware requirements ?
Anthropic Opus 4.5 and sonnet hardware requirements according to perplexity and hugging face. Let`s face it, we will be running multiple models with specialized skills and they will be a fraction of the latest and greatest. Who does have the hardware to run it anyway 😉 Power consumption is also nothing easy to handle, a lot of solar panels or some small creek next to the office could do but otherwise… Perplexity told me that it costs…. On the other hand for gpt-oss-120b We’re releasing two flavors of these open models: MXFP4 quantization: The models were post-trained with MXFP4 quantization of the MoE weights, making gpt-oss-120b run on a single…
-
How to fix, debug and improve your android tv with AI
The Power of AI-Assisted Hardware Debugging Got issues with Your android tv ? Tell copilot to connect to it, analize the lot and provide a feedback. It`s the gist. Longer explanation is that even if You have no idea You can try to utilize an LLmemes to do it for You. They already know the api, have some kind of documentation. Understand to use android debug bridge (adb) to get the proper data. Below what i got fixed and some examples of usage for LLM + ADB + prompt engineering to fix my crashing Youtube app on my Sharp Aquos Android TV. Even got some power saving recommendation and privacy…
-
First principles methodology in AI by Aristotle – 5 step framework
First principles methodology is the practice of breaking a problem down to its most fundamental truths. What we know to be the absolute truth(s). Then we try reasoning upward to build new solutions with what we know to be the fundament. Instead of copying what’s been done before ( haha, said no developer ever). This methodology goes back to Aristotle, the ancient Greek philosopher who first articulated the idea of reasoning from “first principles.” What Is a First Principle? A first principle is a basic, foundational truth that cannot be deduced from anything else. It’s the bedrock of a problem: In AI, first principles might be: Anything else like framework…